The Graphics Processing Unit
CPU:
- wide variety of data structures
- large code bases
- can have multiple processors, but each run code in a mostly serial fashion
- consist of fast local caches
- using clever techniques to avoid stalls
GPU:
- less chip area dedicated to cache memory and control logic
- lantency is higher
- large set of processors(shader core), often numbering in the thousands
- process data in parallel fashion
thread:
each pixel shader invocation for a fragment ( not equal to CPU thread )
warp:
threads use the same shader program are bundled into groups, called warps by NVIDIA, wavefronts by AMD
2000 threads, warps on NVIDIA GPU contain 32 threads => 2000/32=62.5=>63 threads
more registers needed with each thread↑ -> threads↓ warps can be resident in the GPU↓
warps that are resident are said to be in flight and this number is called the occupancy
influence efficiency:
- shader program’s structure: =>occupancy
- dynamic branching: =>if

This is the logical model of the GPU. The real implement on hardware: physical model
- unified shader design => vertex/pixel/gemotry/tessellation/… share a common programming model
have the same instructuin set architexture ( ISA ) - A processor that implements this model is called common-shader core in DirextX.
- A GPU with such cores is saied to have a unified shader architecture
HLSL can compiled to virtual machine bytecode, intermediate language ( IL or DXIL )
draw call : invoke the graphics API to draw a group of primitives
- uniform input: keep constant throughout a draw call => constant register
- verying input: varies for each vertex or pixel =>temporary register
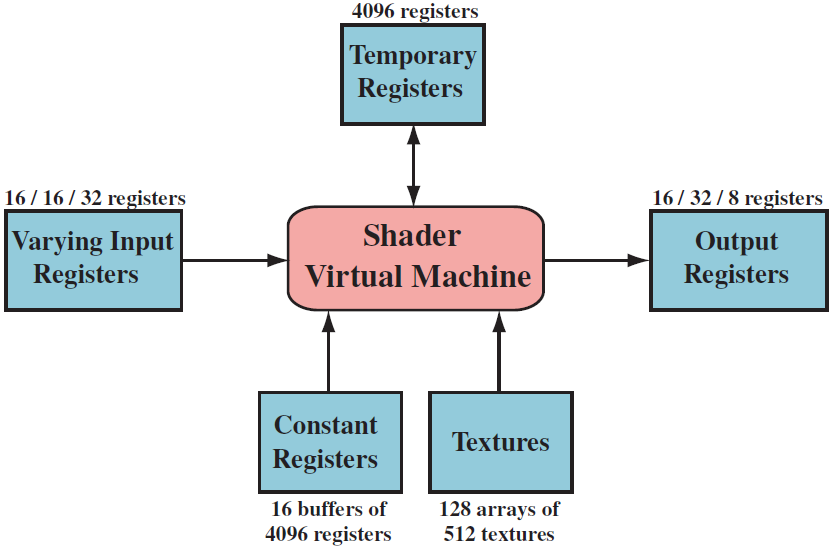
flow control:
- static:
based on the values of uniform inputs, the flow of the code is constant over the draw call - dynamic:
based on the values of varying inputs, each fragment can execute the code differently
- AMD&DICE: Mantle API->Vulkan (API), SPIRV (intermediate language), works from workstations to mobile devices
- Apple: Metal
- OPENGL ES ( embedded system) -> WebGL
DirectX: input assembler -> vertex shader
=> an example where the physical model often differs from the logical
Tessellation Stage:
hull shader
tessellator
domain shader
curved surface
LOD
Geometry Shader:
add / delete / modify /… primitives
MRT:
multiple render targets => deferred shading
- DX11: UAV, unordered access view, allow write access to any location
- OpenGL: SSBO, shader storage buffer object
ROV: rasterizer order views, like UAV, but guarantee data are accessed in order
early-z:
merge testing -> pixel shader
but if change of discard z-depth in pixel shader, early-z can’t be used
computer shader:
- post-processing
- particle system
can access data generated on the GPU